大模型评估数据集
基础常识推理
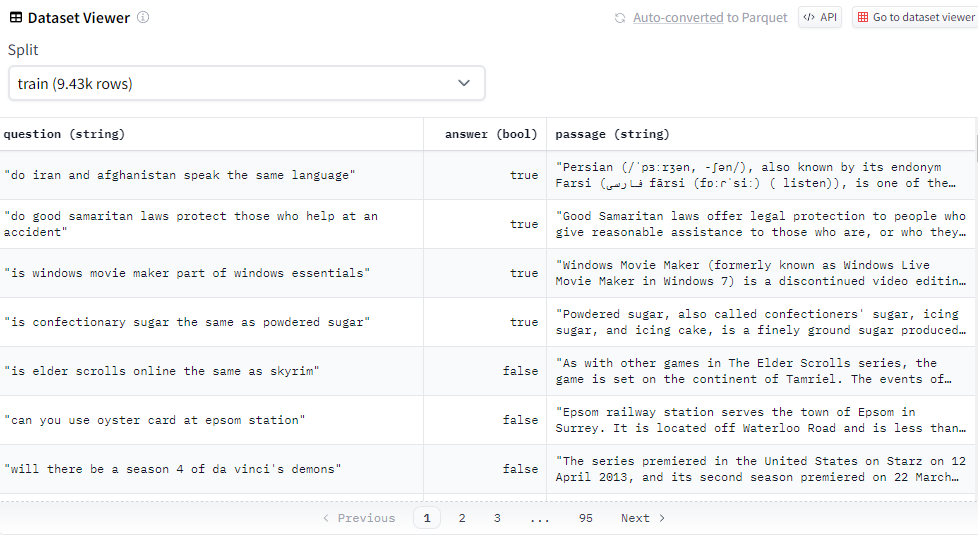
BoolQ
PIQA(Physical Interaction: Question Answering)
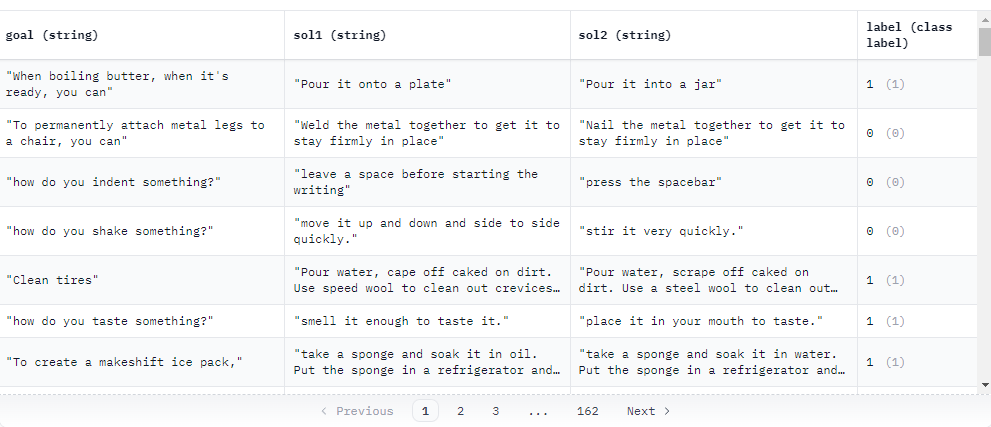
- goal: the question which requires physical commonsense to be answered correctly
- sol1: the first solution
- sol2: the second solution
- label: the correct solution. 0 refers to sol1 and 1 refers to sol2
SIQA(Social Interaction QA)
We introduce Social IQa: Social Interaction QA, a new question-answering benchmark for testing social commonsense intelligence. Contrary to many prior benchmarks that focus on physical or taxonomic knowledge, Social IQa focuses on reasoning about people’s actions and their social implications. For example, given an action like “Jesse saw a concert” and a question like “Why did Jesse do this?”, humans can easily infer that Jesse wanted “to see their favorite performer” or “to enjoy the music”, and not “to see what’s happening inside” or “to see if it works”. The actions in Social IQa span a wide variety of social situations, and answer candidates contain both human-curated answers and adversarially-filtered machine-generated candidates. Social IQa contains over 37,000 QA pairs for evaluating models’ abilities to reason about the social implications of everyday events and situations.
The data is encoded in JSON Lines Format:
- context: A context describing a sitation
- question: A question probing commonsense reasoning about motivation, emotional reactions etc.
- answerA: The first answer choice
- answerB: The second answer choice
- answerC: The third answer choice
HellaSwag
专门针对欺骗机器的推理题。研究基于场景的常识推理的数据集。它包含70,000个关于场景的多项选择问题:每个问题来自两个领域中的一个——activitynet或wikihow,并提供四个答案选项,描述了场景中接下来可能发生的事情。正确答案是下一个事件的(真实)句子;而另外三个错误答案是通过对抗生成并经过人工验证的,旨在欺骗机器而不是人类。
WinoGrande

ARC-e & ARC-c
The ARC dataset consists of 7,787 science exam questions drawn from a variety of sources, including science questions provided under license by a research partner affiliated with AI2. These are text-only, English language exam questions that span several grade levels as indicated in the files. Each question has a multiple choice structure (typically 4 answer options). The questions are sorted into a Challenge Set of 2,590 “hard” questions (those that both a retrieval and a co-occurrence method fail to answer correctly) and an Easy Set of 5,197 questions. Each are pre-split into Train, Development, and Test sets as follows:
- Challenge Train: 1,119
- Challenge Dev: 299
- Challenge Test: 1,172
- Easy Train: 2,251
- Easy Dev: 570
- Easy Test: 2,376
OBQA
OpenBookQA is a new kind of question-answering dataset modeled after open book exams for assessing human understanding of a subject. It consists of 5,957 multiple-choice elementary-level science questions (4,957 train, 500 dev, 500 test), which probe the understanding of a small “book” of 1,326 core science facts and the application of these facts to novel situations. For training, the dataset includes a mapping from each question to the core science fact it was designed to probe. Answering OpenBookQA questions requires additional broad common knowledge, not contained in the book. The questions, by design, are answered incorrectly by both a retrieval-based algorithm and a word co-occurrence algorithm. Strong neural baselines achieve around 50% on OpenBookQA, leaving a large gap to the 92% accuracy of crowd-workers.
Additionally, we provide 5,167 crowd-sourced common knowledge facts, and an expanded version of the train/dev/test questions where each question is associated with its originating core fact, a human accuracy score, a clarity score, and an anonymized crowd-worker ID (in the “Additional” folder).
Closed-book Question Answering
原数据集是可以参考一个evidence,该项为了评估大模型zero-shot,不加入evidence
Natural Questions
Natural Questions Dataset is a question answering dataset. Questions consist of real anonymized, aggregated queries issued to the Google search engine. An annotator is presented with a question along with a Wikipedia page from the top 5 search results, and annotates a long answer (typically a paragraph) and a short answer (one or more entities) if present on the page, or marks null if no long/short answer is present. The public release consists of 307,373 training examples with single annotations, 7,830 examples with 5-way annotations for development data, and a further 7,842 examples 5-way annotated sequestered as test data.
In total, annotators identify a long answer for 49% of the examples, and short answer spans or a yes/no answer for 36% of the examples.Annotators identify long answers by selecting the smallest HTML bounding box that contains all of the information required to answer the question. These are mostly paragraphs (73%). The remainder are made up of tables (19%), table rows (1%), lists (3%), or list items (3%).
TriviaQA

TriviaQA is a reading comprehension dataset containing over 650K question-answer-evidence triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts and independently gathered evidence documents, six per question on average, that provide high quality distant supervision for answering the questions.
阅读理解
RACE

The ReAding Comprehension dataset from Examinations (RACE) dataset is a machine reading comprehension dataset consisting of 27,933 passages and 97,867 questions from English exams, targeting Chinese students aged 12-18. RACE consists of two subsets, RACE-M and RACE-H, from middle school and high school exams, respectively. RACE-M has 28,293 questions and RACE-H has 69,574. Each question is associated with 4 candidate answers, one of which is correct. The data generation process of RACE differs from most machine reading comprehension datasets - instead of generating questions and answers by heuristics or crowd-sourcing, questions in RACE are specifically designed for testing human reading skills, and are created by domain experts.
数学推理
MATH

MATH is a new dataset of 12,500 challenging competition mathematics problems. Each problem in MATH has a full step-by-step solution which can be used to teach models to generate answer derivations and explanations.
GSM8k

GSM8K is a dataset of 8.5K high quality linguistically diverse grade school math word problems created by human problem writers. The dataset is segmented into 7.5K training problems and 1K test problems. These problems take between 2 and 8 steps to solve, and solutions primarily involve performing a sequence of elementary calculations using basic arithmetic operations (+ − ×÷) to reach the final answer. A bright middle school student should be able to solve every problem. It can be used for multi-step mathematical reasoning.
代码生成
HumanEval
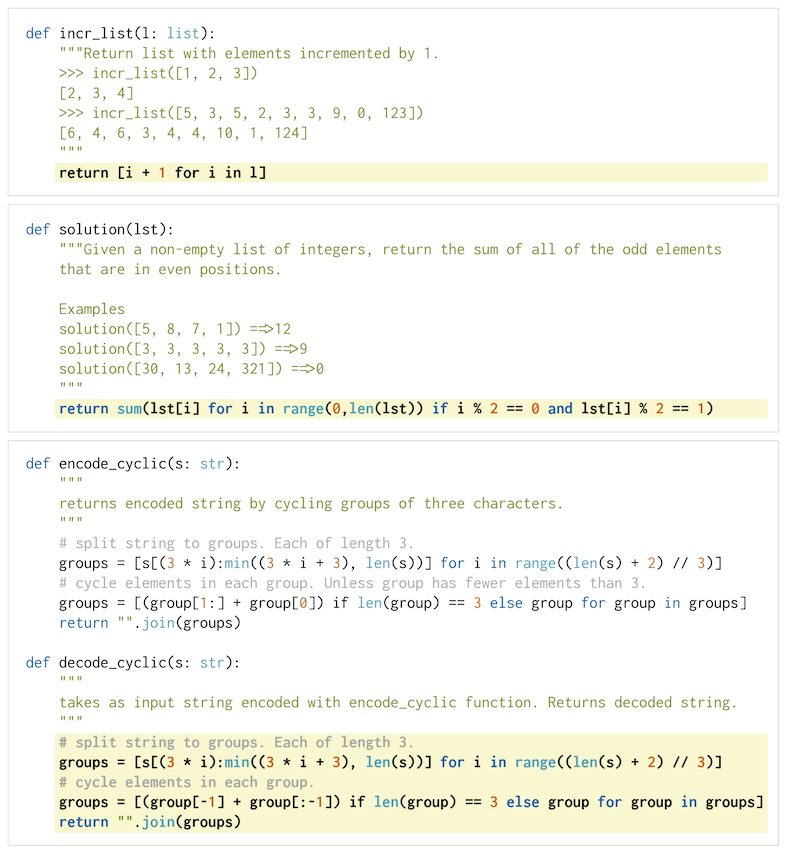
This is an evaluation harness for the HumanEval problem solving dataset described in the paper “Evaluating Large Language Models Trained on Code”. It used to measure functional correctness for synthesizing programs from docstrings. It consists of 164 original programming problems, assessing language comprehension, algorithms, and simple mathematics, with some comparable to simple software interview questions.
MBPP
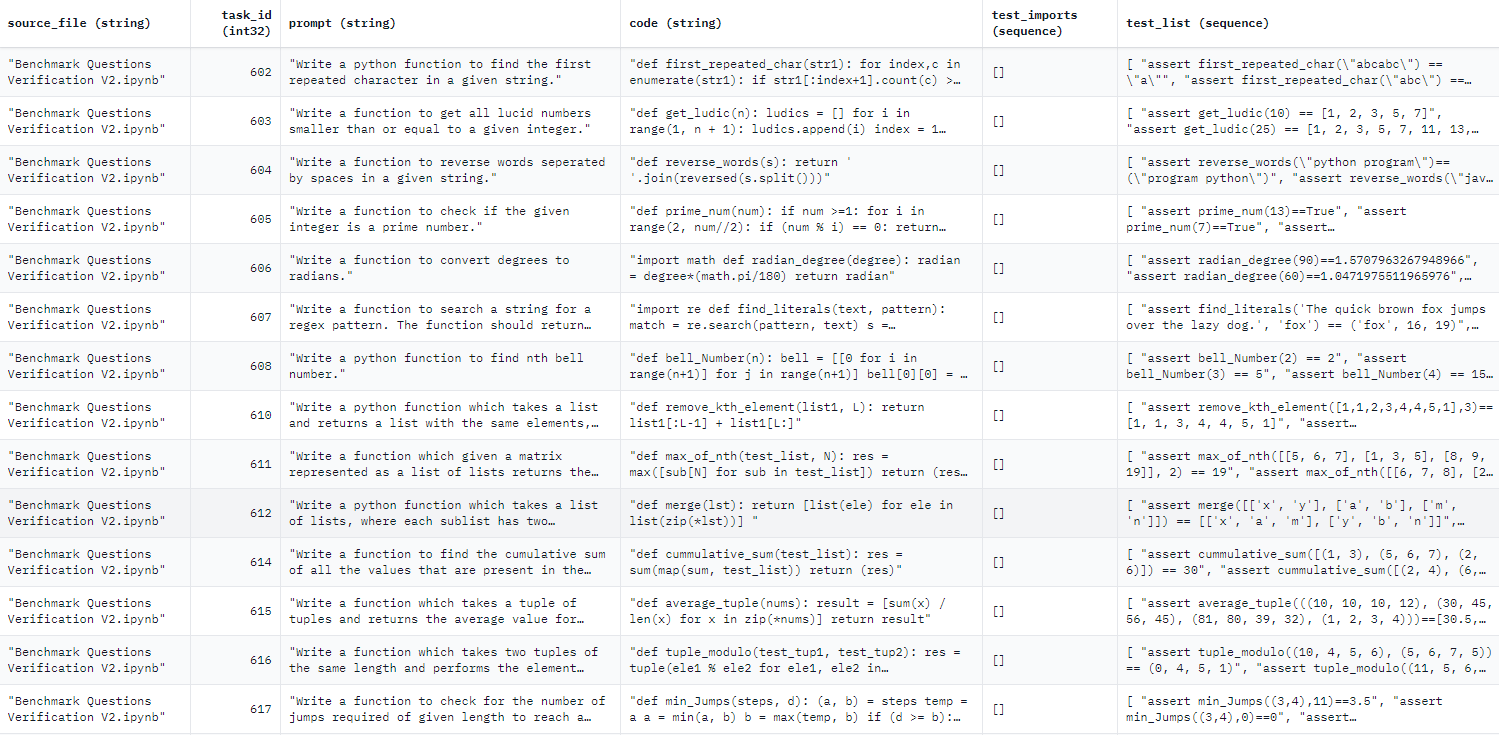
The benchmark consists of around 1,000 crowd-sourced Python programming problems, designed to be solvable by entry-level programmers, covering programming fundamentals, standard library functionality, and so on. Each problem consists of a task description, code solution and 3 automated test cases.
Massive Multitask Language Understanding
MMLU

MMLU (Massive Multitask Language Understanding) is a new benchmark designed to measure knowledge acquired during pretraining by evaluating models exclusively in zero-shot and few-shot settings. This makes the benchmark more challenging and more similar to how we evaluate humans. The benchmark covers 57 subjects across STEM, the humanities, the social sciences, and more. It ranges in difficulty from an elementary level to an advanced professional level, and it tests both world knowledge and problem solving ability. Subjects range from traditional areas, such as mathematics and history, to more specialized areas like law and ethics. The granularity and breadth of the subjects makes the benchmark ideal for identifying a model’s blind spots.