混合精度训练
浮点型
什么是浮点型
小数点位置约定在固定位置的数称为定点数,小数点位置约定为可以浮动的数称为浮点数。
深度学习中常见的浮点型格式
单精度FP32
半精度FP16
半精度BF16(安培架构)
浮点型表示方法

其中符号位1为负数,0为正数,指数位采用补码,尾数位采用原码。指数位存在一个指数偏置项(移码)(exponent bias),偏置项为 而非通常的 ,以FP32为例,偏置项为127,通过偏置项将无符号指数范围从1~254(全1和全0用来标记特殊值)转移到 -126~127 避免指数位同样出现一个符号位与浮点型符号位增加比值问题的复杂度。因同一个数对应的尾数有多种表示,因此IEEE 754规定一个规格化方式——尾数第一位为1的形式称为规格化,在这种情况下,尾数省略第一位1,所以FP32中尾数实际为23位但表达24位信息。
其他情况
无穷大(inf)
指数位全为1,尾数位全为0的时候,表示inf,通过符号位不同分别表示+inf和-inf
非数(NaN)
指数位全为1,尾数位不全为0的时候,表示NaN,尾数位第一位为1时表示Quiet NaN,尾数位第一位为0且尾数其他位不为0时表示Signaling NaN,通常推荐qNaN与sNaN在除第一位尾数外保持一致,例如BF16当尾数为1000001时为qNaN,为00000001时为sNaN。
非规格化数字
指数位全为0,尾数位不全为0的时候,以FP32为例,此时不给尾数添加省略的1,可增加表达的精度,减少下溢
零
指数位全为0,尾数位全为0,表示0,通过符号位不同分别表示+0和-0
混合精度训练
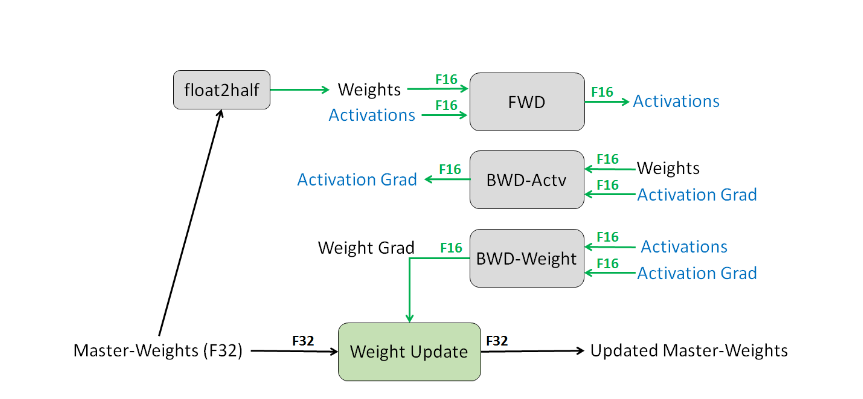
参数精度
Weights, Activations, gradients都使用FP16,另有一份Weights的FP32副本。训练时只有参数更新在FP32的副本上进行,其余都在FP16上进行。
FP32 Copy of Weights
因为梯度和学习率相乘会有不少一部分产生浮点下溢,从而影响精度甚至无法收敛。在一些优化器的情况下可能会导致一阶、二阶动量为0,在平滑不足的情况下,会造成下一step的梯度爆炸。
Loss Scaling
因数值分布问题,大多参数都比较小,所以将指数位缩小,来增加尾数的精度(即小数点后长度),BF16等价于FP16在loss scale factor为8(b’111’)的情况。loss scale处理放在前向传播之后,反向传播之前,并且当流程中存在梯度截断等对梯度有修改的操作时,应将在这些操作前将loss unscale,以确保FP16的梯度截断以及FP32的参数副本更新时可以对齐。
Arithmetic Precision
模型训练时的数值计算只要分三种:vector dot-product(矩阵乘法)、reductions(对向量全部元素求和)、point-wise operations(逐位操作)。对于矩阵乘法,伏特架构支持输入FP16,得到FP16或FP32的输出,对于有些模型,不输出FP32会降低精度,尽管输出FP32后仍需转换为FP16。对于元素求和(通常存在于BN,softmax等结构上)也应对其进行FP32计算在转换为FP16进行读写,因为这里的瓶颈来自于内存带宽而不是计算,因此不会产生额外的耗时。逐位操作的瓶颈仍然位于内存带宽,所以用FP32和FP16都是可以的。
相关问题
为什么在不同部分占的位宽是固定的情况下,仍叫做浮点型?
如果表示方法为符号位+整数位+小数位,25.05可以表达为 1 * (25 + 0.05),此时"点"(小数点)固定于"25"和"05"中间。如果以浮点表示可以看作 1 * 25.05 * 10^0 , 1 * 0.2505 * 10^2, 1 * 2505.0 * 10^-2,此时"点"是"浮动的"。
为什么浮点型设计不是符号位、整数位、小数位?
该表示方法称之为定点型,可以增加表达的范围,减少小数精度。可能浮点型更看重精度而不是范围。
有必要复制一份FP32 parameter(weight)吗?
该方法提出时,并没有考虑gradient checkpoint技术,认为相比activations占用不算大。另外因为参数中的精度分布如下图所示,乘以学习率后大部分会产生下溢,并在其实验表明,该行为能保持模型性能不变,否则性能会下降到约80%。