GPT Series
GPT1
Improving Language Understanding by Generative Pre-Training
前言
- 将之前词向量等无监督称之为
Semi-supervised learning,将GPT1这种无监督称之为Unsupervised pre-training(作为Semi-supervised learning的子集)
Framework
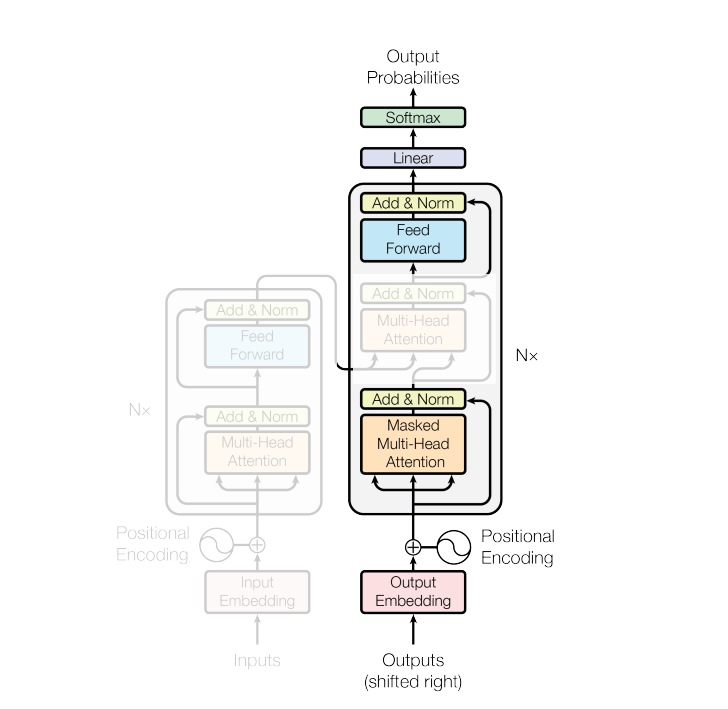
Unsupervised pre-training
给定一个句子,极大似然
为上下文窗口大小
Supervised fine-tuning
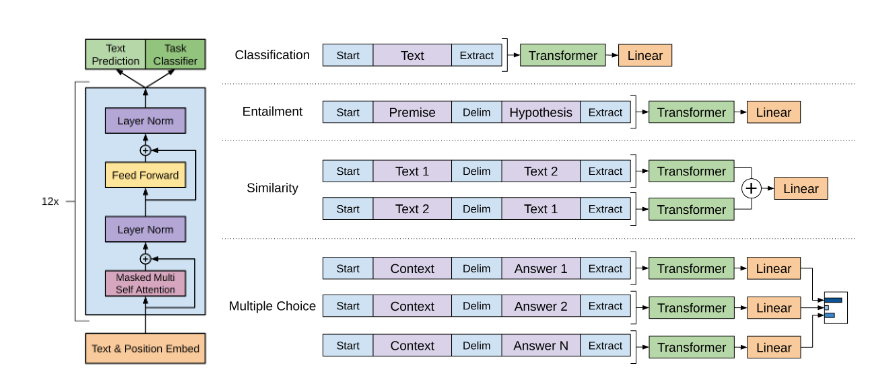
Setup
BERT-base对标于GPT1
| GPT1 | BERT-base | |
|---|---|---|
| 参数量 | 110M | 110M |
| 数据集 | BooksCorpus(800M words) | BooksCorpus & English Wikipedia(2,500M words) |
| vocabulary | BPE | WordPiece |
| position embeddings | 可学习 | 可学习 |
| 发布时间点 | 2018.06 | 2018.10 |
GPT2
创新点
- zero-shot
- prompt (使用该范式,但未明确定义该范式)
相比于GPT1
| GPT1 | GPT2 | |
|---|---|---|
| 参数量 | 110M | 1.5B |
| 数据集 | BooksCorpus(800M words) | WebText(Reddit<40 GB) |
WebText来自于Common Crawl(一个公开爬虫脚本)
GPT2各版本参数量
| Parameters | Layers | |
|---|---|---|
| 117M | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
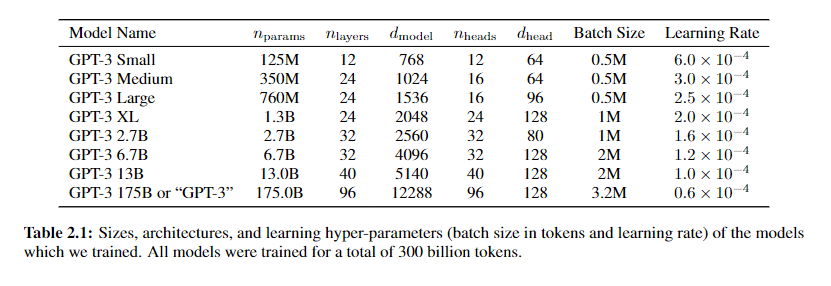
GPT3
创新点
- few-shot(非fine-tuning,无梯度计算)
Framework
meta-learning
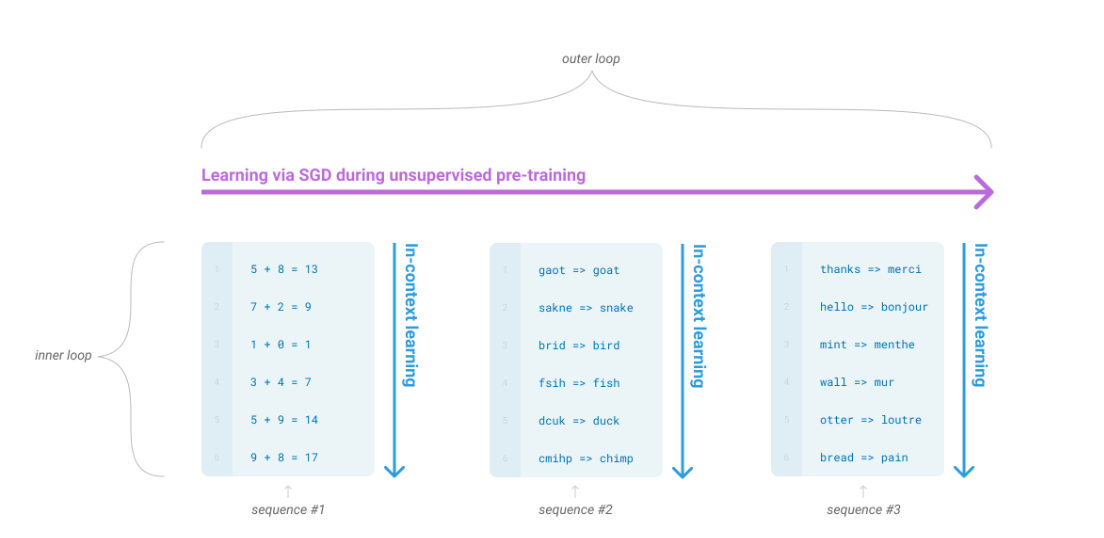
in-context learning

Setup
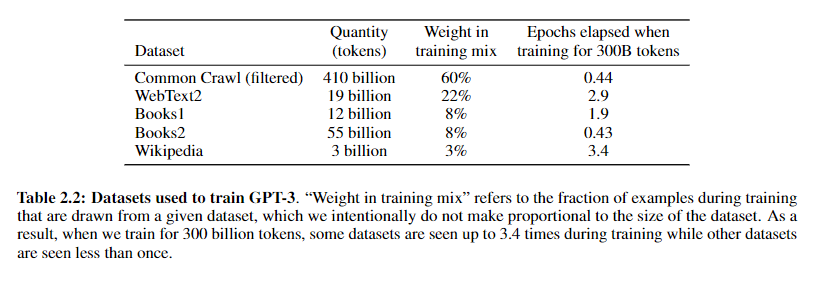
training-data 训练了一个回归模型,去过滤WebText中的数据
InstructGPT & ChatGPT
We trained this model using Reinforcement Learning from Human Feedback (RLHF), using the same methods as InstructGPT, but with slight differences in the data collection setup.
ChatGPT is fine-tuned from a model in the GPT-3.5 series, which finished training in early 2022.
GPT-3.5 series is a series of models that was trained on a blend of text and code from before Q4 2021.
Framework
通过OpenAI API获取到的一些prompts去微调了GPT-3(175B),对模型返回的N个答案,让人进行排序并反馈给模型(RLHF),得到InstructGPT(1.3B)
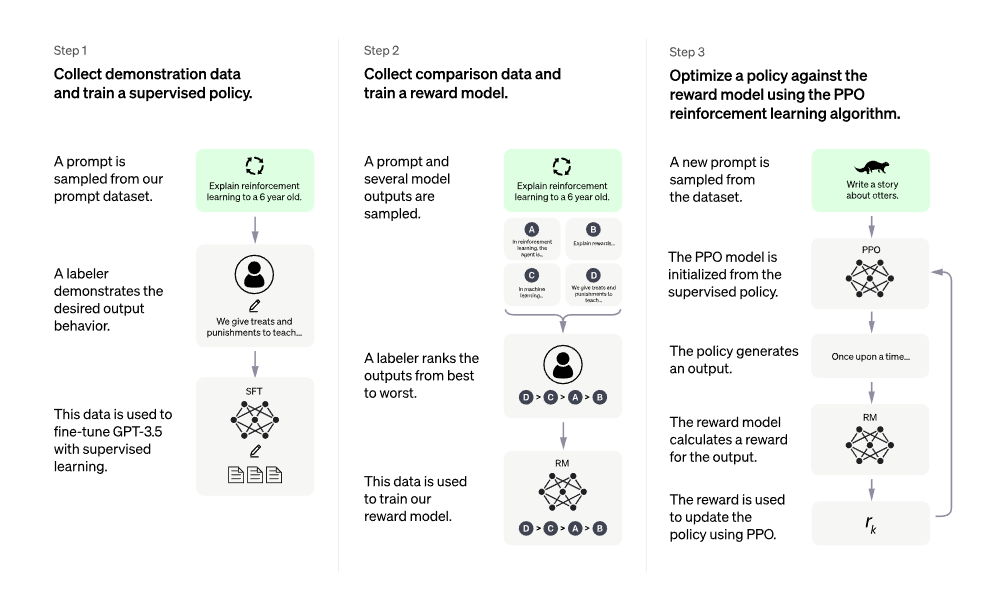
- SFT——对收集到的质量好的prompt采用人工标注答案后,对GPT3.5进行微调(成本过大)
- 采用人工对模型返回的几种结果,进行排序来训练RM(在线学习耗时久,成本也不小)
- 得到RM后,通过RL来训练模型
通过把最后的softmax换成全连接映射为维度为1的标量当作RM的奖励gt。RM模型loss(Pairwise Rank Loss)
整体优化目标函数
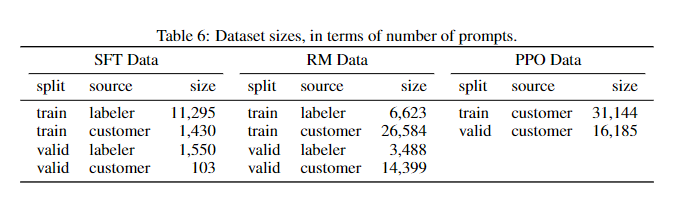
Setup
The SFT dataset contains about 13k training prompts (from the API and labeler-written), the RM dataset has 33k training prompts (from the API and labeler-written), and the PPO dataset has 31k training prompts (only from the API).