KV Cache
自回归模型的推理过程
想看懂KV Cache部分,首先需要清晰的理解自回归模型在推理过程是怎样的。
推理过程不同于SFT部分(相比于SFT低效太多,或者说训练部分并没有体现自回归范式),每次(输入流经整个模型)得到一个token,我们首先讨论按照训练时进行推理的方式,即每次输入上一轮的输入+上一轮生成的token序列的最后一位。循环迭代直到达到停止条件。
但加入KV Cache之后,真正推理时每次仅需输入上一轮生成的token,而不是当前生成的完整输出。两种推理差异如图所示。
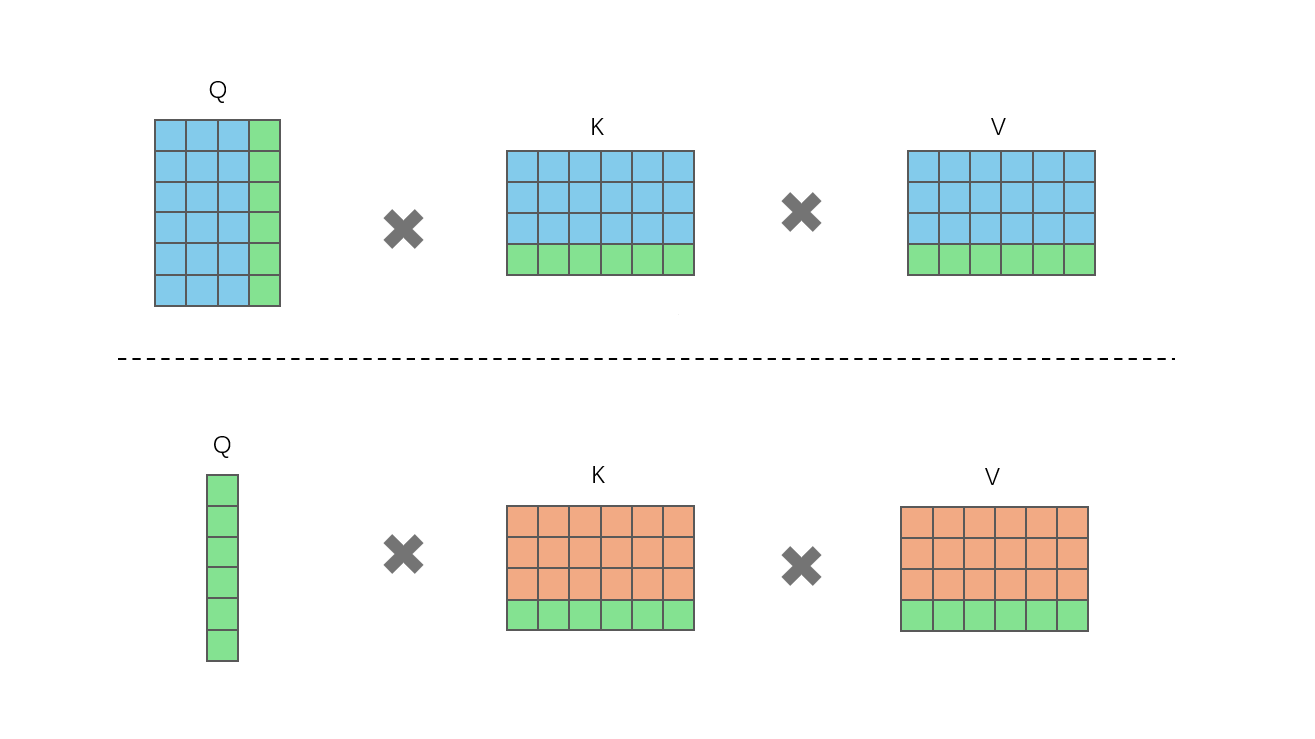
其中绿色的为上一轮生成的token,蓝色为之前的token,橘色的在token表示上等同于蓝色。蓝色和绿色都为需要即时计算,橘色则为缓存部分
多轮自回归的QKV的变化
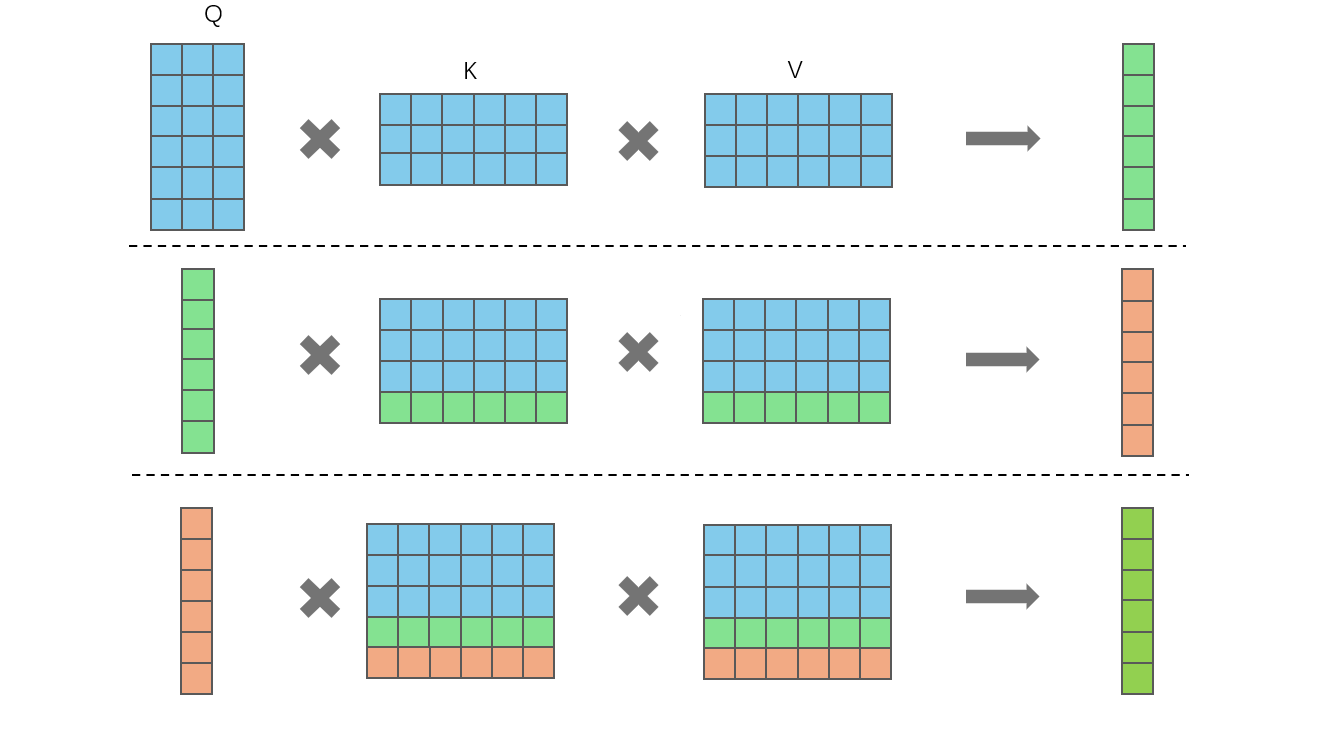
第一行为第一次输入,此时缓存是空的,输入的query也需要为整个question(prompt+question)生成对应的QKV,然后将K和V缓存起来;第二行即自回归的第二轮,将第一行的输出(一个token id)再次输入,得到一个QKV(长度皆为1),然后将该KV与各自的缓存KV合并起来,再进行attention,并把此时的KV缓存更新;第三行继续重复此过程直到达到停止条件。
KV Cache 带来的计算量差异
计算量差异主要来自于Q长度的减少,以及KV和 , 之间的计算,我们记一次浮点乘法加一次浮点加法为1FLOP的话(CPU为2FLOPs,GPU根据其硬件实现表现也不同)
不使用KV Cache时,QKV与其W的计算量为 ,使用KV Cache时,QKV与W的计算量为 ;另一个受影响的部分为attention部分,其不使用KV Cache时, 的计算量为 ,使用KV Cache时的计算量为 。因此使用KV Cache可以带来 的计算量降低。
KV Cache 带来的显存差异
如图二所示,会多出 个参数,其中 为 batch_size, 为 length, 为hidden_size, 为num_blocks。对于半精度,KV Cache的显存占用为 。当无KV Cache时,Q的输入也如图一所示,需要更多的显存,若中间计算值不能及时回收的话,显存占用等价于K/V,所以差异在 ~ 之间。