记:一次接口性能优化(cpu模型推理 + ES)
优化结果
线下
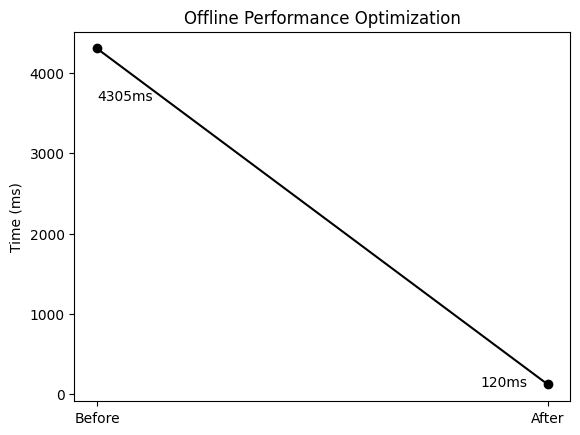
线上
线上因为服务和ES都在AWS,所以速度会更快,具体结果还在测试中(后面会介绍优化后,docker部署的一个需要注意的地方)
优化过程
性能分析
在优化性能时,首先分析耗时在哪里,此次优化的是一个Python的flask接口,内部的主要分两部分——ES查询 + bert推理。此时选取一个python性能分析工具cProfile,即可获取一个分析结果
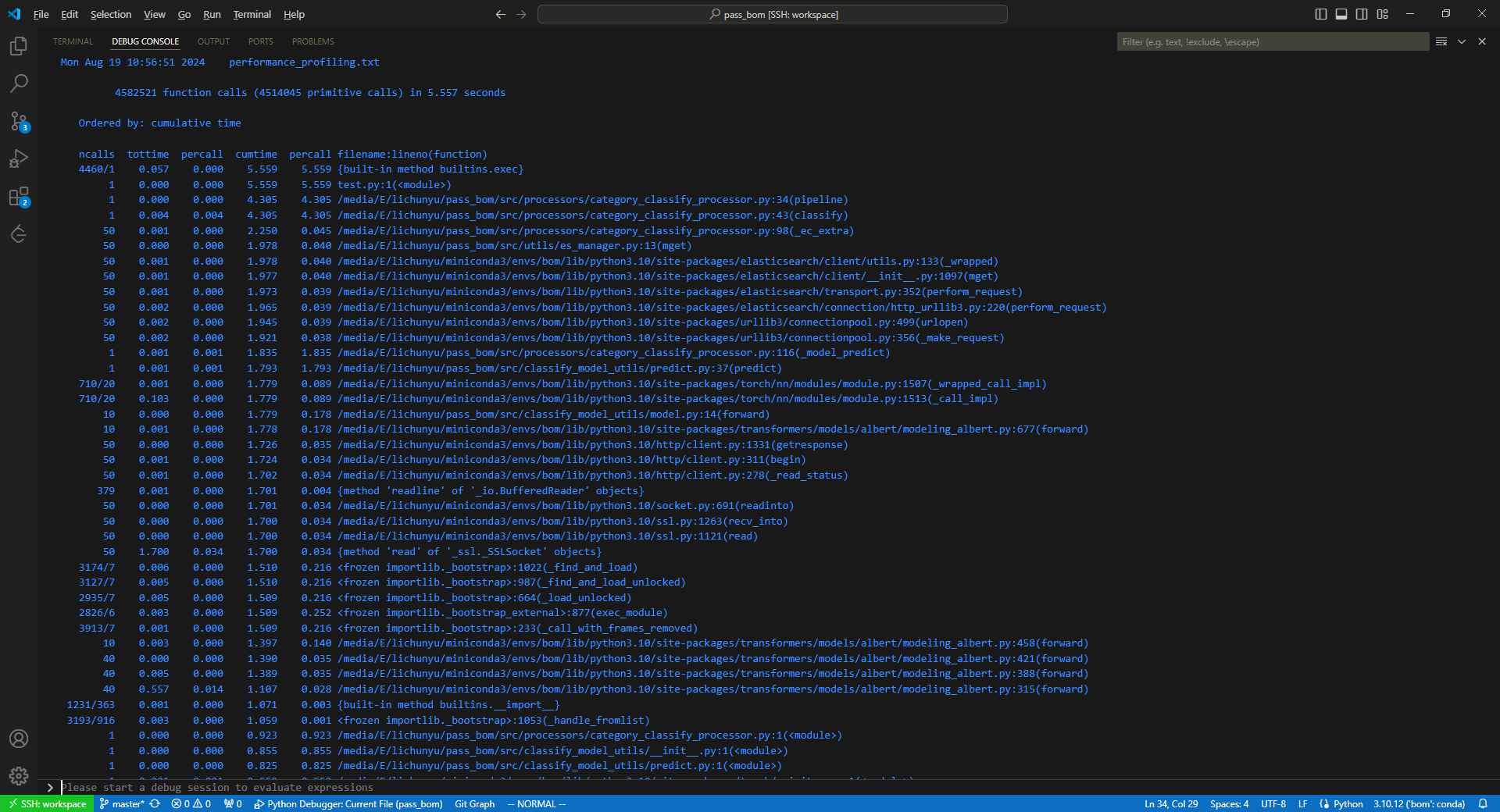
根据分析结果,我们可以看到此接口进行了50次ES查询以及10次模型推理(forward)。
优化思路
- 50次ES查询是否可以合并为1次来减少网络开销
- 模型推理有什么更快的方式
针对第一项,我们首先查看其业务逻辑,发现ES查询和模型推理互相并没有依赖关系(最开始的设想中,我误以为ES查询依赖于模型推理的结果,考虑做模型输出结果的预测,提前查询ES来进行预测命中,减少后续的查询时间)。而50次查询中可能会存在重复查询,但要对应每次查询的结果,所以我们对50次查询进行汇总去重,并保留了和原数据的映射关系,查询后再映射回去。
针对第二项,因该项目部署服务器为CPU机器(无GPU),选用GGML库,对推理模型改用C/C++进行重写,又经文档发现HF对应的rust版本tokenizer性能非常好,并有社区提供开源的C++ binding。针对该模型,创建了bert.cpp项目,具体性能差异参考README。其中性能差异中的python代码已经相对该项目进行了优化(1793ms VS 260ms)。但仍然有比较大的性能优化空间——动态图转静态图、tokenzier差异、计算图数学等价、语言抽象成本差异。实际测试中,因该项目预测的本文特点是批次较多、长度都比较短、计算图节点不多的情况下,cpu相比gpu计算的劣势甚至被省去的异构内存拷贝所弥补,性能相当可观。
实际优化过程
遇到的问题我们放到后面再讲,我们先展示一下实际优化完做了些什么
更进一步
- 将50次ES查询去重汇总成1次,再分割成N次查询
- 协程模型推理和N次查询
开发初始时,计划只针对50次查询的场景构建固定维度计算图。但项目需求,改为针对动态维度构建静态计算图,优化了mask计算,对于项目无关的计算图节点进行剪枝。再将该项目打包成共享库,供Python使用,此时发现推理大概耗时26ms(还有优化空间),50次汇总一次ES查询时间要大于26ms,所以再将ES查询拆分成N份,通过事件循环,先将N个请求发出去,然后将cpu执行权交给模型推理,推理完成后再获取ES查询结果。此时最理想的情况是IO耗时尽量逼近cpu计算,所以需要对拆分N份后每个chunk的请求尽可能在30ms附近。
遇到的问题
使用的文件协议在开发完,发现存在更新更完善的协议
开发时,因GGML完全没有开发文档,参考了部分examples。文件协议选用了.ggml,在刚刚开发完的时候就发现了更新的文件协议.gguf :( ,犹豫之后,放弃了协议的更新——首先这部分不影响使用,只是需要多一个tokenzier.json文件,以及代码更加硬编码。在不影响性能的情况下,决定在后面优化完,有空的时间再进行更新。

计算图输出的结果与Pytorch不对齐
GGML提供的softmax没有维度的指定以及很多操作只支持低维度的操作,因此需要更多的permute和reshape。这里花费了大量的时间去debug查看结果,因为问题反应在输入与pytorch相同的矩阵进行矩阵乘法,但输出却不同,误以为是维度或转置处理上的问题(事实上,在更早的节点,只有第一个列向量是相同的,因为没有完全打印矩阵,没有早点发现,矩阵作为float*保存),首先Vscode非常友好的在同一窗口下可以debug不同语言,方便对比。但是应该早点实现一个格式化打印函数,早点发现真正没对齐的节点。
打包共享库时,所依赖的tokenizer库没有提供PIC
构建共享库供Python使用时,因tokenizer库没有PIC库,通过递归设置set_target_properties(XXX PROPERTIES POSITION_INDEPENDENT_CODE ON)仍然不能成功设置PIC,没有更深入的研究,选择了更暴力的add_compile_options(-fPIC),因此该项目的tokenizer的子模块是自己fork后修改的。不确定是否有在高层项目中CMakelist指定低层编译选项的方式(待研究)。
内存泄露
在开发时,针对每个函数都编写了对应的单元测试和性能测试(包括python针对so的调用)。但是实际加入到业务项目中时,在一次多次调用时,发现申请的用来计算的内存缓冲区进行近乎成倍的增长(表现为:每调用一次,申请的缓冲区被多占用一倍,直到缓冲区被完全占满)。具体的代码如下
1 | void py_bert_batch_predict_logits(bert_ctx *ctx, const char **sentences, int32_t n_sentences, int32_t n_threads, float **logits) |
首先怀疑ggml_free函数没能正确释放掉。但是查看源码后,认为没有问题。其次认为ggml_cgraph *gf = bert_build_dynamic(ctx, ctx0, token) 构建计算图后,计算图并没有随着对应的buf释放而释放掉(特指内部指向内存缓冲区的使用末端地址没有归0即缓冲区头部)。DEBUG后发现每次缓冲区的使用都是从头部开始。最后打印计算图,发现循环推理的时,每次输入的长度意外的增加了。罪魁祸首竟是偷懒使用的static关键字
1 | void bert_batch_tokens::init_input_ids(std::vector<std::vector<int>> &input_ids, int32_t pad_id) |
为了方便C++和Python的兼容使用,选用的容器来中间保存输入数据,但是ggml的内存拷贝需要保证数据的内存连续。使用flat、mask两个容器来初始化在依赖.data()获取这段连续内存数据,若不添加static关键字,这段实际内存会随着该函数的退出而释放,却成为了后面多次调用时,日渐增长的原因。因此每次再额外.clear()置空该容器。
打包docker时报错Segmentation fault
非常有趣的部分。在本地完全验证完后,上线前进行docker本地构建的验证,一切还算顺利,但是启动时加载完模型后,竟然报错Segmentation fault,首先考虑到的某个指针不符合预期,猜想是新的环境链接的库有问题

对比物理机上正常运行的链接库,发现并无异常。但是修改cmake后仍然无法产生对应报错的core文件(似乎与apport有关)。使用GDB运行调试,内容也是非常的粗暴,直指传入动态库的指针非法。因此我对代码添加了一些打印信息后运行
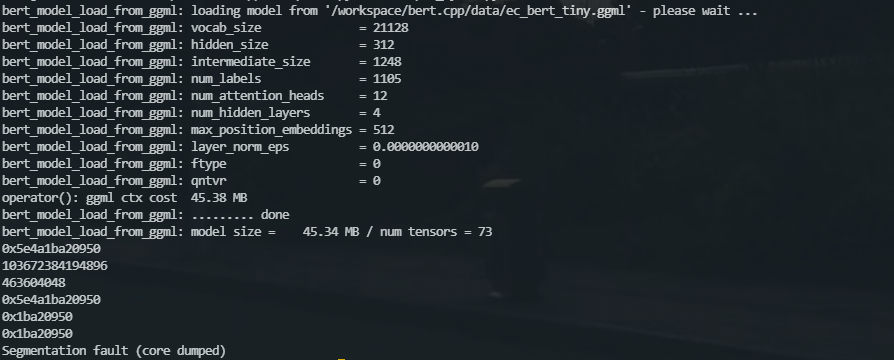
- 第一行为Python接受到的指针(在次之前,我确定了C++的指针与返回Python的指针的值是一致的,图示中省略了这一部分)
- 第二行为Python中print后的结果
- 第三行为再次传入C++中以int类型print的结果(错误操作,但是从结果中收到了启发)
- 第四行为Python中再次以16进制打印的结果
- 第五行为再次传入C++中以指针类型打印的结果(该函数只进行打印)
- 第六行为再次传入C++中以指针类型打印的结果(该函数通过指针,获取其成员的某个属性,但是打印在函数最开始的时候)
首先我们可以看到传入C++中的指针与Python中的指针发生了变化,因此Seg fault的原因显而易见,但问题变得更加难以解决(发生在语言交互过程中)。不过既然是传入指针不对,起码排除了C++代码问题的嫌疑。首先猜想是Docker中的地址有二次映射,导致二次传入时发生了变化。但第五、六行连续两次的传入保证了一致性,似乎排除了这一想法。这时候观察第二、三行的两个数字,两个结果相差的意外的大,我首先产生了一个错误的想法(但是"弄巧成拙",找到了原因,事实在上面这个打印图中已经暴露的原因,但之前打印的结果数值溢出,没能发现),在Python和C++侧,大小端记法是相反的,二次打印的时候符号显示有了问题,于是我就找了个在线网站,又觉得没有\x不清晰,干脆转了2进制。

参考2进制排除了大小端问题。却发现后29位是完全相同的,这时候反应过来,Python传入C++时,指针被意外的截断为4字节(事实上,从这一次图示的打印就可以直接发现的,却兜了一大圈)。不过此时我仍然认为是Python解释器的位数或C++编译的位数存在问题。于是分别编写了脚本打印位数,发现都是8字节即64位。到此为止,我已经确定是Python的c_void_p类型在传入时被截断为4字节了,但是查阅文档,并没有对应的解决方案,而底层的源码也不好修改。最后放弃了一定的可读性,将Python针对此返回和参数的类型改为了c_uint64类型,此时该Seg fault得以解决。
总结
汇总以上优化,不外乎减少网络消耗,保证IO和CPU资源的利用率,将ES查询的并行压力交给ES服务端,优化推理的CPU消耗并将CPU计算的压力通过动态库得以绕过GIL实现并行计算。

还可以做的优化部分
首先bert.cpp README中描述了未来可继续的工作,此外针对该业务场景仍然可优化的地方
- 除去ES查询和模型推理,额外的业务逻辑使用了大量的循环和借助
pandas的操作(构建DataFrame时的索引建立等)仍然可以优化 - 通过ES的ping和一次查询,根据延迟与CPU计算的时间,计算最优的ES分块查询个数。(查询的id个数与时间的复杂度似乎为O(1),具体的计算方式未深入研究)
bert.cpp项目的计算图包含了argmax,但是业务场景中并不需要,可以剪枝掉。- 选择合适的依赖的底层线性计算加速库(我参考GGML一个issue的测试结果,似乎部分加速库反倒更慢)
- 镜像的构建中,将构建镜像和部署镜像分开,将中间依赖(例如rust)移除
- 量化模型