PagedAttention
接着上文,LLM为了增加推理速度提出了KV Cache,但KV Cache会增加显存的消耗,从而对高并发不友好,
因此提出了一些解决方案,PagedAttention就是其中一种较为高效的解决办法。
什么是PagedAttention
PagedAttention并不是一个新的网络结构,而是一种显存优化方案。
PagedAttention的原理
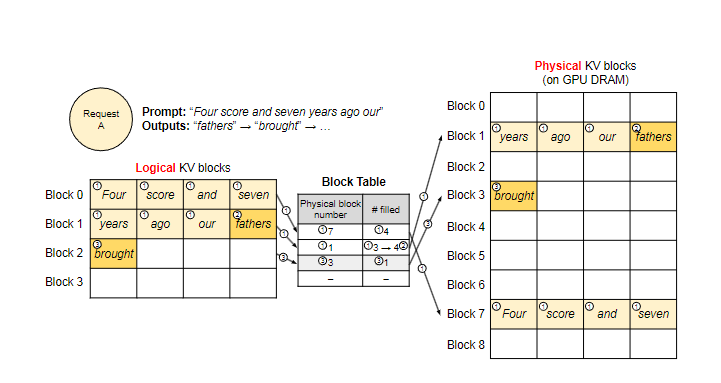
使用KV Cache的大模型的显存分布

其中,KV Cache中的显存主要浪费在保留显存、内部碎片、外部碎片

且因为KV Cache是动态的(相比于模型的其他部分),参考内存的处理方式,提出了显存分页。
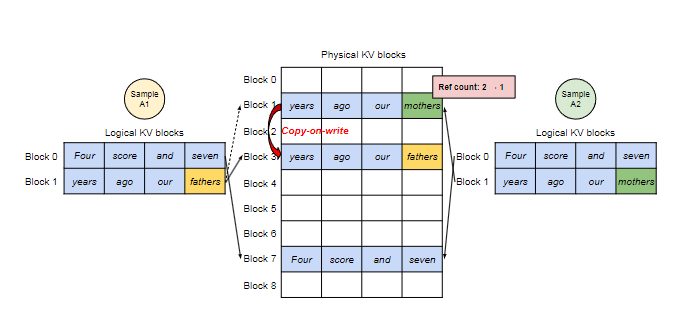
针对解码的优化
Parallel Sampling
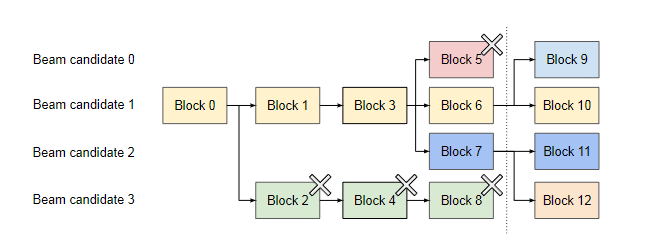
Beam Search
为什么显卡没有虚拟内存和内存分页
- GPU设计的目的是为了并行计算,对显存要求低
- GPU的显存往往都不大
- GPU对带宽要求很高,虚拟内存会增加开销
扩展
这里我们自然会想到一些有趣的联想
为什么目前的LLM接口都提供一个system prompt字段?
为什么LLM接口(openai chatgpt)的收费竟然和max_tokens字段有关?
All articles in this blog are licensed under CC BY-NC-SA 4.0 unless stating additionally.